ПРОГНОЗ
Целью этого этапа является создание вероятностного прогноза на уровне SKU и магазина. На этом этапе механизм будет собирать существующие данные (прошлые продажи, стокауты, отображаемый период) для прогнозирования будущих продаж. Однако мы не можем забывать, что это первый раз, когда продукт поступает в магазины, поэтому история продаж и остатков недоступна для анализа. Однако, даже когда нет исторических данных о продажах для конкретных продуктов, которые планируется размещать, Nextail также проводит расчеты на основе оценок спроса. Каким образом?
Используя данные о продуктах, признанных "схожими" с теми, которые планируется размещать.
 Как задаются аналогичные продукты?
Как задаются аналогичные продукты?
- Автоматически в Nextail и под контролем экспертов со стороны клиента.
- Предположения на основе визуального сходства, сходства характеристик, цены, раздела каталога и места, занимаемого в коллекции.
Как рассчитывается прогноз спроса?
Это автоматический процесс, который учитывает разнообразные аналогичные продукты, различия в моделях сезонности и сети магазинов, ассортиментные эффекты и т. д.

Прогнозы спроса, основанные на данных по аналогичным продуктам, менее точны, чем те, которые основаны на фактических продажах, поэтому обычно не все остатки отправляются за один раз, и позже в прогноз вносятся корректировки.
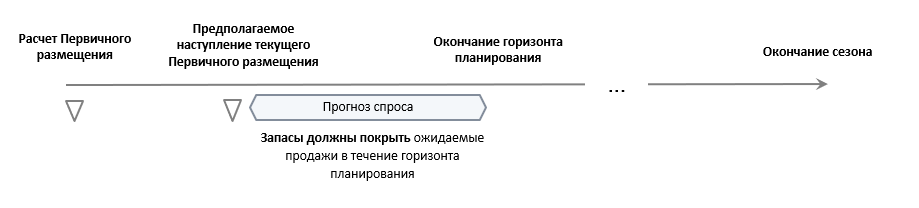
Поскольку окончание горизонта планирования и окончание сезона достаточно далеки друг от друга, есть небольшая/незначительная вероятность того, что остатки закончатся раньше, чем наступят оба эти момента.
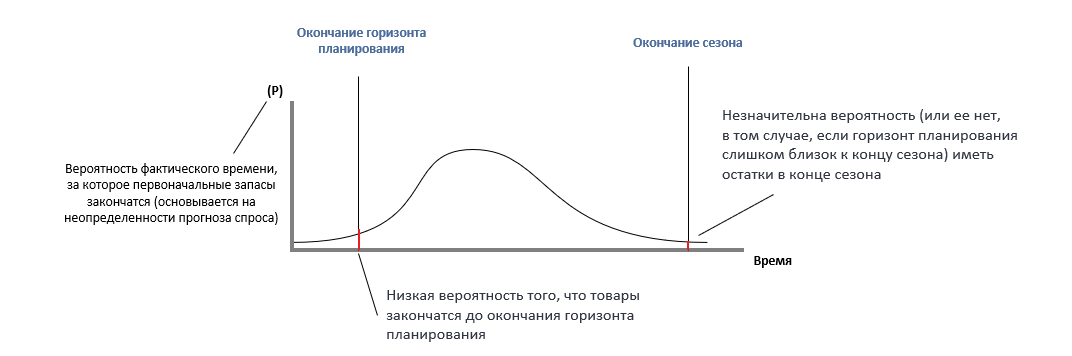
Несмотря на то, что прогноз спроса при первичном размещении не очень точен, он все же позволяет запустить эффективное распределение остатков новых товаров, вводящихся в магазины (до тех пор, пока горизонт планирования не очень близок к окончанию сезона).
Расчет размерной кривой
Как только прогноз спроса станет доступен для каждого продукта и магазина, он рассчитывается на уровне "продукт-размер (SKU)”, учитывая ожидаемые размерные кривые для этой комбинации продукта и магазина.
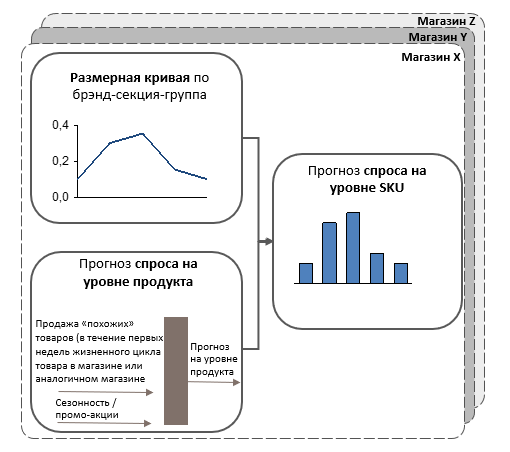
- Размерные кривые для разных магазинов могут отличаться на 20% -25%: размерные кривые должны рассчитываться с высокой точностью, чтобы не допустить переизбытка или недостатка отдельных размеров.
- Мы используем информацию по аналогичным продуктам, чтобы построить соответствующие размерные кривые для каждого продукта: Чтобы компенсировать возможную нехватку точных подробных данных, в алгоритме заложены дополнительные стратегии расчета.
