
- Ventes historiques
- Délais de production
- Horizon de planification
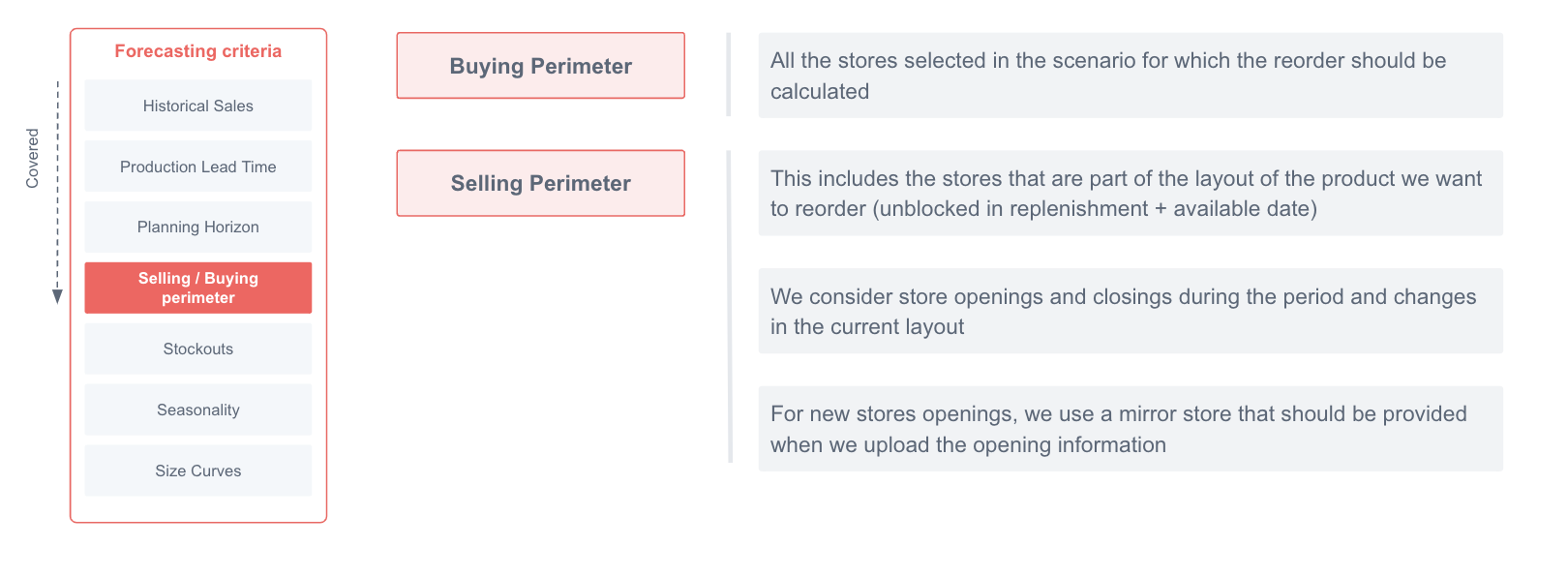
- Périmètre d'achat / vente
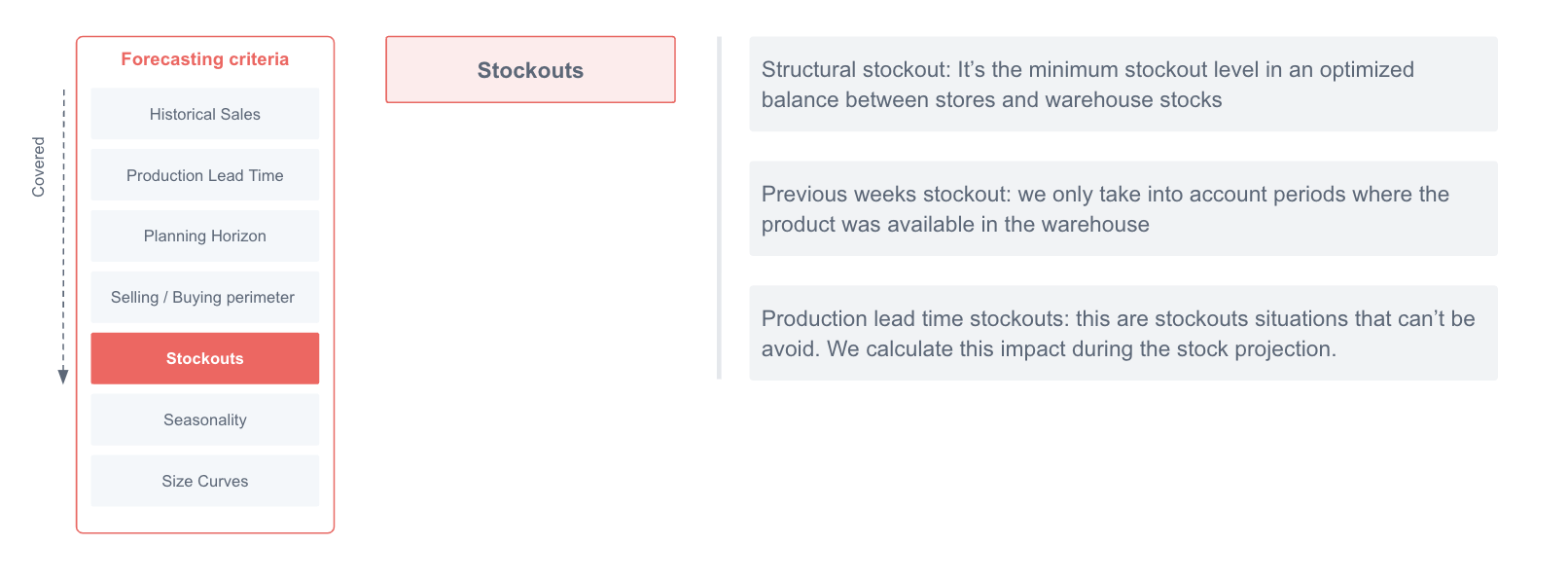
- Ruptures de stock
- Saisonnalité
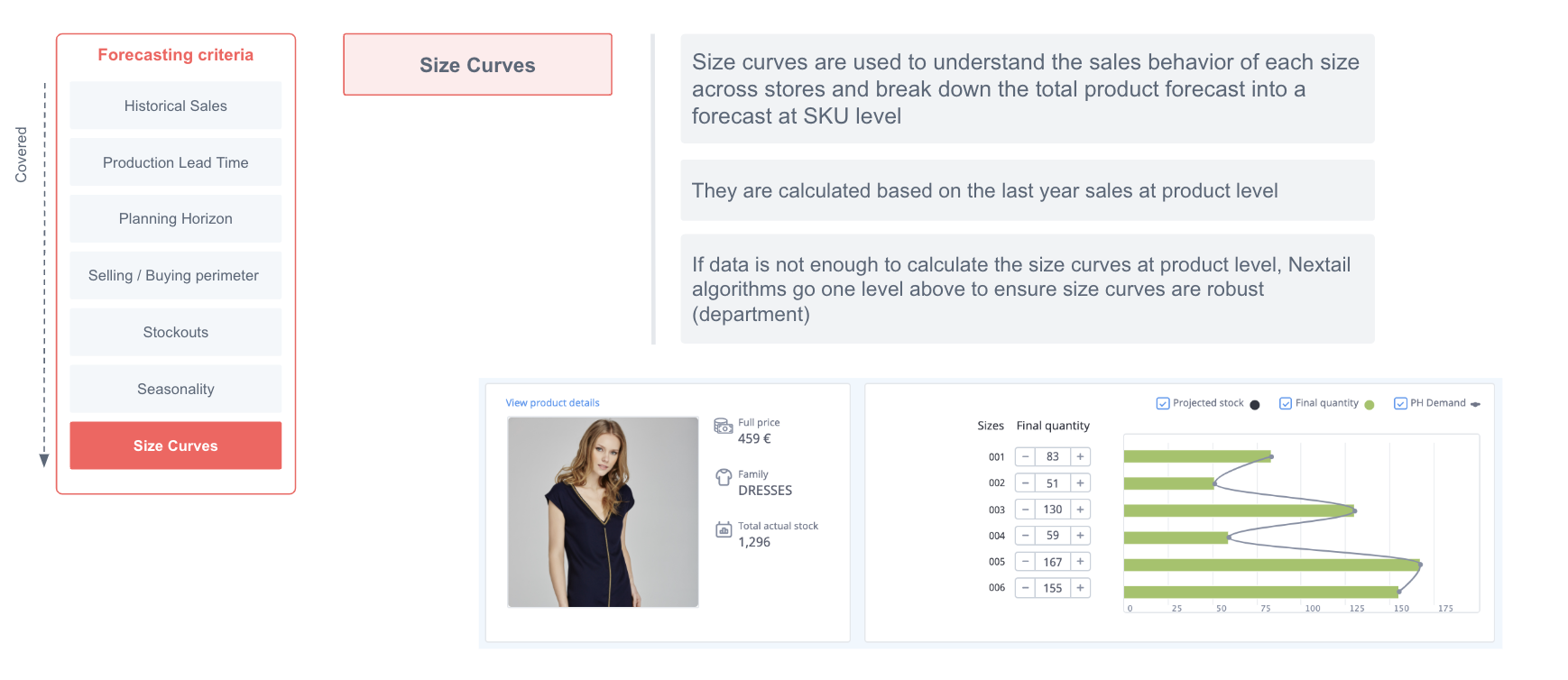
- Courbes de taille
La chronologie du calcul de la prévision de la demande est définie par les semaines historiques, le délai et l'horizon de planification.

Différents périmètres de magasins peuvent être pris en compte lors du calcul des prévisions de chaque scénario
Les ruptures de stock, tant à l'entrepôt qu'en magasin, jouent également un rôle dans l'estimation de la proposition de réapprovisionnement.
L’effet sur les ventes des événements récurrents est automatiquement pris en compte par les algorithmes de Nextail

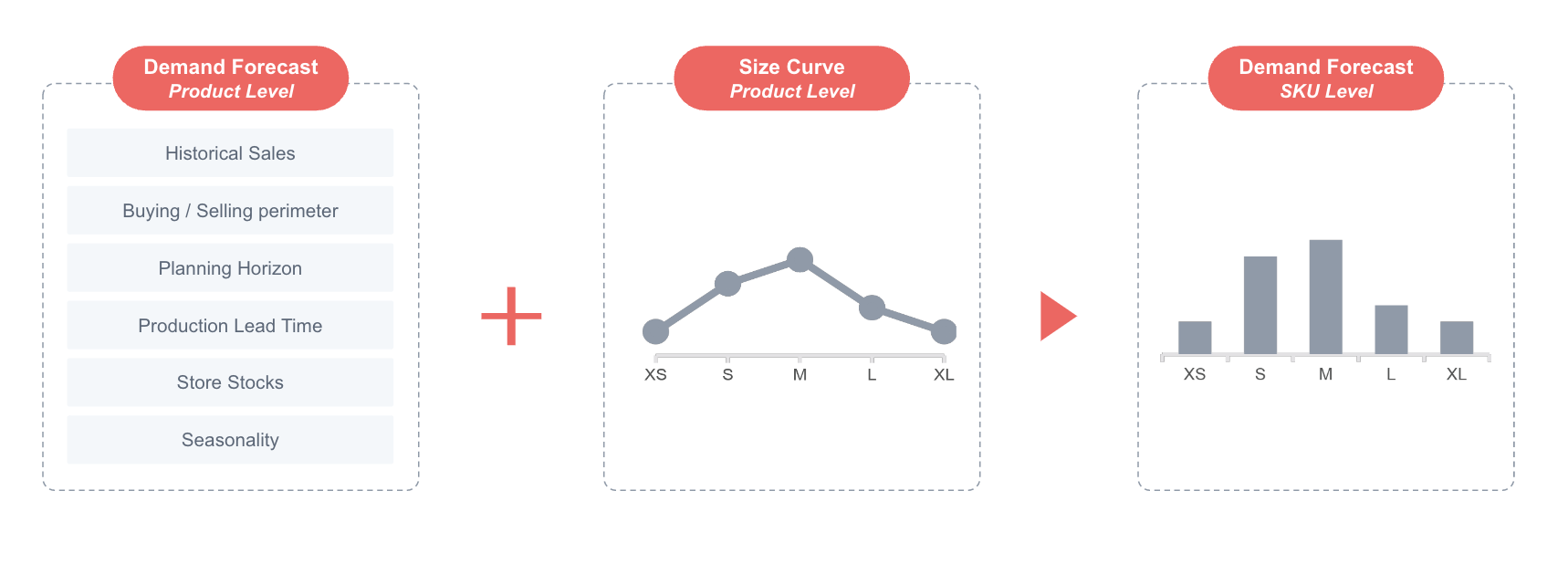
Les courbes de tailles sont recalculées dans chaque scénario pour décomposer au niveau SKU les Forecast obtenus pour chaque produit
Une fois la prévision de demande au niveau produit calculée, les courbes de taille sont utilisées pour la décomposer et obtenir une prévision par SKU.
Promotions
Les promotions sont des événements spéciaux qui ont un effet changeant temporaire sur la demande d’un produit pendant la durée de leur activité. À l’heure actuelle, les promotions peuvent être soit des démarques, soit d’autres types d’événements.
Dans le cadre Nextail, les promotions sont exprimées sous la forme d'un facteur multiplicatif de demande appelé coefficient de promotions. Par exemple. s'il y a un coefficient de promotions x2 entre deux dates, certains magasins et certains produits spécifiques, cela signifie que la demande (éventuellement les ventes) sera deux fois supérieure à la normale.
Le pipeline Promotions est en charge de récupérer et de calculer les coefficients de promotion d'un groupe de produits dans un réseau de magasins, au niveau produit-magasin-date.
Les clients sont responsables de la définition de ces coefficients pour les promotions à venir dont ils savent qu'elles auront un impact sur la demande. Ce sont les futurs coefficients de promotion. Une fois la période promotionnelle terminée, les coefficients définis sont recalculés à partir de données de ventes réelles pour obtenir quel a été l'impact réel sur la demande. Ce sont les coefficients de promotion passés. Les promotions ont donc deux effets dans nos prévisions :
1. Multipliez la demande future estimée par les clients par les futurs coefficients de promotion. Illustrons-le :
-Le client estime une demande x2 sur le produit Random Sweater 101 au cours de la deuxième semaine de l’année en raison d’une démarque spéciale.
-Une fois appliquée, la saisonnalité prévue est de 200 SKU au cours de cette semaine.
-Un coefficient de promotion future de 2 est appliqué, donc désormais 400 SKU sont le résultat de nos prévisions.
2. Corrigez (normalisez) les données de ventes sur lesquelles nos prévisions sont formées, en les divisant par les coefficients de promotion passés.
Au cours de la deuxième semaine de l'année, le client a finalement vendu 300 SKU.
Le coefficient réel obtenu est de 300/200 = 0,5 (50 %).
Pour les prévisions futures, nous prendrons ce coefficient de promotion passée de 0,5 afin de normaliser les ventes pendant la période de soldes au lieu d'utiliser le coefficient de promotion future d'origine (qui était de 100 %).
Il est possible que plusieurs promotions affectent le même produit dans les mêmes magasins et pendant la même période. Dans ce cas, seul le coefficient maximum est pris en compte.
Disponibilité passée
Les informations de disponibilité passée fournissent un fichier avec les combinaisons jour-magasin-produit où un produit est disponible dans les données historiques utilisées pour la prévision. L'importance d'informer correctement sur la disponibilité d'un produit nous permet d'estimer la demande plutôt que les ventes.

Quelle est la différence?
La demande est la quantité que nous vendrions si le magasin était ouvert et approvisionné tous les jours
Les ventes correspondent à ce qui s'est réellement produit et sont toujours inférieures ou égales à la demande.
Nous supposerons que la demande est égale aux ventes lorsque le produit est disponible.
Le modèle de disponibilité passée couvre les cas suivants :
-Rupture de stock en entrepôt (voir ci-dessous dans la section rupture de stock en entrepôt)
-Date de première disponibilité. La date de première disponibilité du produit est définie comme la médiane des premières dates auxquelles le produit est disponible dans chaque magasin, ainsi le produit sera considéré comme indisponible pour toutes les dates précédant la date de première disponibilité du produit. Nous utilisons la médiane (qui est similaire à une moyenne) car elle est considérée comme une approche plus robuste qu'un min ou un max.
-Dates de fermeture des magasins. Un magasin est considéré comme ayant connu une période de fermeture s’il ne réalise aucune vente pendant deux jours consécutifs ou plus. Tous les produits sont considérés comme indisponibles dans un magasin lorsque ce magasin est en période de fermeture.
Ces trois cas sont les cas dans lesquels les données historiques ne sont pas considérées comme bonnes pour prévoir l'avenir, elles seront donc exclues. Si ces restrictions laissent un produit avec moins de 50 % de jours de disponibilité (par rapport au nombre de semaines utilisé comme historique), les jours de rupture de stock commençant au début de la période seront utilisés dans les prévisions jusqu'à ce qu'il y ait suffisamment de jours disponibles.
Rupture de stock en entrepôt
Dans les prévisions à long terme (LTF), une rupture de stock ne signifie pas exactement un stock nul, car les clients deviennent souvent progressivement plus conservateurs en matière de réapprovisionnement, de sorte qu'ils n'arrivent pas à un stock nul dans la plupart des cas.
Lorsqu’un produit est considéré en rupture de stock dans l’entrepôt, la solution de réapprovisionnement évitera d’utiliser les données de ventes de ces dates.
Pour évaluer si un produit est en rupture de stock WH, nous appliquons plusieurs logiques.
Seuil de quantité minimum : correspond à la quantité d'unités de chaque produit qui doivent être dans le WH pour que le produit ne soit pas considéré comme en rupture de stock. Est mesuré comme la relation entre les unités disponibles d'un produit dans le WH et le nombre de magasins qui doivent être couverts. Ce pourcentage est un paramètre et est actuellement fixé à 10 %.
Par exemple, si un produit contient 20 unités en WH et qu'il doit couvrir 300 magasins (10 % équivaut à 30), alors ces unités ne sont pas considérées comme suffisantes et le produit est en rupture de stock.
Courbes de taille pour la rupture de stock : Les tailles d'un produit n'ont pas toutes le même poids et la même importance dans le volume des ventes du produit, nous utilisons les données des courbes de taille pour déterminer un bon critère de rupture de stock en entrepôt et éviter que les tailles résiduelles telles qu'un XXXL puissent déterminer le rupture de stock de l'ensemble du produit.
Pour déterminer quelles tailles seront prises en compte dans les critères de rupture de stock, nous sélectionnons les tailles les plus vendues qui totalisent plus de 80 % du volume total des ventes (au niveau du produit et non au niveau du magasin). Les autres tailles sont considérées comme « non pertinentes » et ne seront pas utilisées pour calculer la rupture de stock.

Dates de rupture de stock corrigées: Un produit devra être en rupture de stock à WH pendant au moins 10 jours pour qu'il soit considéré comme indisponible. Passé ce délai, il faudra qu'il dispose de 5 jours de stock pour qu'il soit à nouveau considéré comme disponible.
Si ces restrictions laissent un produit avec moins de 50 % de jours de disponibilité (par rapport au nombre de semaines utilisé comme historique), les jours de rupture de stock commençant au début de la période seront utilisés dans les prévisions jusqu'à ce qu'il y ait suffisamment de jours disponibles.
Nouveaux magasins / fermetures de magasins
Parfois, le périmètre de vente change pendant le délai de livraison ou la période de couverture, et nous devons prendre en compte ces changements pour la suggestion de réapprovisionnement. Voici les principales causes des changements et la manière dont l’algorithme les prend en compte :
Ouverture de nouveaux magasins (sans historique préalable) : Afin d'attribuer un poids correct à un nouveau magasin et aux produits dont il dispose, une relation avec un magasin miroir est attribuée. La demande, le périmètre de vente et le stock minimum sont copiés depuis ce magasin miroir depuis la date d'ouverture jusqu'à la fin. Le jour de son ouverture, le magasin est initialisé pour maintenir le stock minimum de toutes les références de son périmètre de vente (tant qu'il y a du stock dans l'entrepôt).
Fermeture du magasin : les dates de fermeture des magasins sont prises en compte lors de la définition des informations de disponibilité passées. Comme mentionné, la fermeture d'un magasin est marquée lorsqu'il y a plus de deux jours consécutifs sans aucune vente et elle influence la disponibilité des produits pendant ces dates.
Dans ce cas, la demande de fermeture du magasin est déjà définie sur 0 pour le jour de fermeture selon la prévision. De plus, il n’y aura aucune considération de stock minimum pour ces magasins. Une dernière chose à considérer est que le stock de ces magasins est conservé "gelé" dans ces magasins dans la version actuelle, ce qui signifie qu'il n'est pas rendu disponible à nouveau dans le réseau de magasins du point de vue de la projection des stocks.
Modifications de la mise en page
Il existe deux concepts principaux qui décrivent la situation de disponibilité pour une combinaison produit-magasin :
- Aménagement intérieur du magasin : Lorsqu'un produit est présent dans un magasin et qu'il est disponible à la vente (ce que l'on mentionne parfois comme étant à l'intérieur du périmètre de vente).
- Aménagement extérieur du magasin mais toujours disponible pour des ventes extraordinaires :lorsqu'un produit n'est pas dans un magasin, mais qu'il est possible de le commander dans d'autres magasins ou depuis l'entrepôt (cela peut se produire par exemple via des demandes en magasin. Parfois, nous décrivons cette situation avec le nom de « à l’intérieur du périmètre d’achat mais hors du périmètre de vente)
Il existe trois états possibles pour une combinaison magasin-produit pour une date donnée:
- Le produit est présent en magasin et peut être acheté en magasin. Le produit est dans la mise en page.
- Le produit n'est pas présent en magasin, mais il peut quand même être commandé parfois. Nous considérons toujours que des ventes pourraient avoir lieu dans ce cas, généralement moins souvent qu'à l'intérieur du réseau. Le produit est considéré comme disponible mais hors mise en page.
- Le produit n'est pas disponible dans le magasin (soit il n'est pas vendu dans le monde entier, soit le magasin est fermé). Cette combinaison n'est jamais disponible dans nos prévisions.
Structure du masque de disponibilité. Exemple

Un magasin de produits peut modifier son état de disponibilité pour l'un de ces changements possibles :
Modifications de l'agencement du magasin (gestion de l'agencement), déplacement des combinaisons magasin-produit de présentes dans le magasin à non présentes et inversement (entre les cas 1 et 2).
Ouverture de nouveaux magasins, reproduisant la demande d'un magasin existant pour tous les produits (y compris les 2 changements précédents).
Fermeture des magasins existants fixant toutes les combinaisons magasin-produit aux dates de fermeture d'un magasin à non disponible (pas disponible du tout, cas 3).
Toutes les modifications apportées à l'état de disponibilité seront reflétées dans les informations de disponibilité pour chaque combinaison produit-magasin-date. De cette manière, notre algorithme de prévision de la demande prendra en compte les variations de disponibilité des produits-magasins.
Les futures modifications de la mise en page peuvent être téléchargées lors de la configuration du scénario.
Ces changements de cap ont bien sûr un impact sur les prévisions. Dans chaque scénario de réapprovisionnement, nous calculons le poids moyen du magasin (pour tous les produits) à la fois dans le cadre des ventes réalisées à l'intérieur et à l'extérieur de l'agencement. Ensuite pour chaque changement, la prévision sera augmentée/diminuée en pourcentage en utilisant le poids du magasin concerné.
Imaginons un exemple. Le client lance un scénario de réapprovisionnement avec 50 produits et 100 magasins. Au sein de tous les magasins, le magasin A n'avait pas la référence 1 dans le layout.
Le client a paramétré qu'à partir du début de l'horizon de planification, le magasin A aura la référence 1 dans l'agencement. La solution calcule le poids du magasin dans les ventes à la fois à l'intérieur et à l'extérieur de la mise en page (en considérant les ventes totales de ce magasin parmi les 50 produits du scénario).
La prévision est ensuite ajustée en considérant qu'il y aura une augmentation des ventes des magasins avec le produit à l'intérieur de l'agencement (proportionnelle au poids de ce magasin) et une diminution des ventes des magasins avec ce produit à l'extérieur de l'agencement.
Courbes de taille
La courbe de taille d'un produit correspond aux poids relatifs de chacune de ses tailles. Ces pondérations sont utilisées pour ventiler nos prévisions du niveau de date de magasin du produit au niveau de date de magasin de SKU. Le poids de chaque taille est basé sur la part des ventes en volume sur l’ensemble des ventes du produit. Par exemple, sur un pull, une taille M a plus de chance d’avoir un volume de ventes plus important et donc un poids plus important qu’une taille XXL.
Le pipeline utilisera par défaut la dernière année de ventes pour calculer ces poids et générer des courbes de taille pour les produits donnés. Illustrons avec un exemple simple :
Produit : Pull aléatoire 101
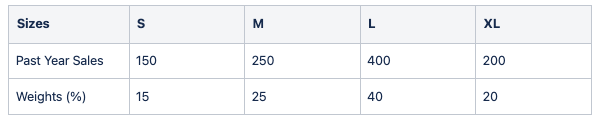
En suivant l'exemple, si nous avons calculé une prévision de 700 références pour le même produit et une certaine période de temps, nous répartirons alors les références en tailles en utilisant des poids préalablement calculés :
Ventes prévues : 700 SKU

Afin d’assurer la robustesse de la courbe de taille, il existe un repli en fonction du volume de ventes de chaque produit. Lorsque les ventes d'un produit sont inférieures à un seuil (200 par défaut) sur la période passée définie (1 an par défaut), les ventes agrégées au niveau famille sont prises en compte pour le calcul des pondérations.
Cette solution de repli agit comme une correction des poids plutôt que comme une substitution. Ainsi, le poids final sera une proportion du poids du produit et du poids de la catégorie de produits sous forme de rapport linéaire (product_sales/threshold). Illustrons-le:
Produit : Pull mauvais vendeur 102

Ventes totales (niveau produit) : 80 SKU
Seuil : 200 SKU
Repli dans la catégorie famille : Pulls aléatoires

Ratio poids = Ventes totales / Seuil = 80/200 = 0,4 (40%)
Poids finaux pour le pull Bad seller 102
poids final = poids de secours * (rapport 1-poids) + poids du produit * rapport poids

Cette solution de repli sera appliquée de manière récursive jusqu'à ce que le seuil soit satisfait. Ainsi, garantissant la robustesse.
Toutes les explications ci-dessus s'appliquent au SizeCurveAutocomparablesPipeline qui est actuellement utilisé.
Les solutions de secours utilisées lors de la réorganisation sont le niveau du produit, le niveau de la famille et la distribution normale.
Poids du magasin de produits
Les pondérations de chaque combinaison de magasins de produits sont estimées pour ventiler notre demande prévisionnelle du niveau produit au niveau produit-magasin. Ceci est ensuite utilisé pour calculer la projection de stock au niveau du magasin et pourrait donc avoir un impact sur la proposition de réapprovisionnement finale. Le poids de chaque magasin de produits est basé sur la part des ventes en volume et en disponibilité du produit dans tous les magasins.
Illustrons avec un exemple simple :
À partir des données de ventes, nous regroupons la quantité vendue par produit en magasin.

Nous estimons la moyenne des ventes par magasin et estimons le poids de chaque magasin par rapport à toutes les données de magasins disponibles.

Nous attribuons les poids estimés précédents par magasin à tous les produits disponibles dans chaque magasin et multiplions la disponibilité du produit, cela signifie que lorsqu'un produit n'est pas disponible dans un magasin, son poids sera de 0.

Pour estimer le poids réel de chaque produit-magasin, nous pondérons le poids attribué (Poids disponible) par le poids total disponible de chaque produit dans tous les magasins. Par exemple pour le produit 1 le poids total disponible est de 0,636, puisqu'il n'était pas disponible en magasin 2.

Ainsi dans cet exemple, les 100% des ventes du produit 1 correspondent aux ventes du magasin 1 car il est dans le seul magasin où il est disponible.
Saisonnalité
La saisonnalité est utilisée dans les prévisions à long terme de la même manière que dans les prévisions à court terme. Cela signifie qu'il est utilisé pour désaisonnaliser les ventes historiques, puis appliqué dans la période de l'horizon de planification.
La configuration de saisonnalité est différente de celle utilisée dans la prévision à court terme car en réapprovisionnement, nous n'avons pas strictement besoin d'avoir une granularité au niveau du magasin (car nous nous intéressons à la prévision générale du produit) et donc le niveau de repli pourrait différer .
